
GANs N’ Roses Pytorch
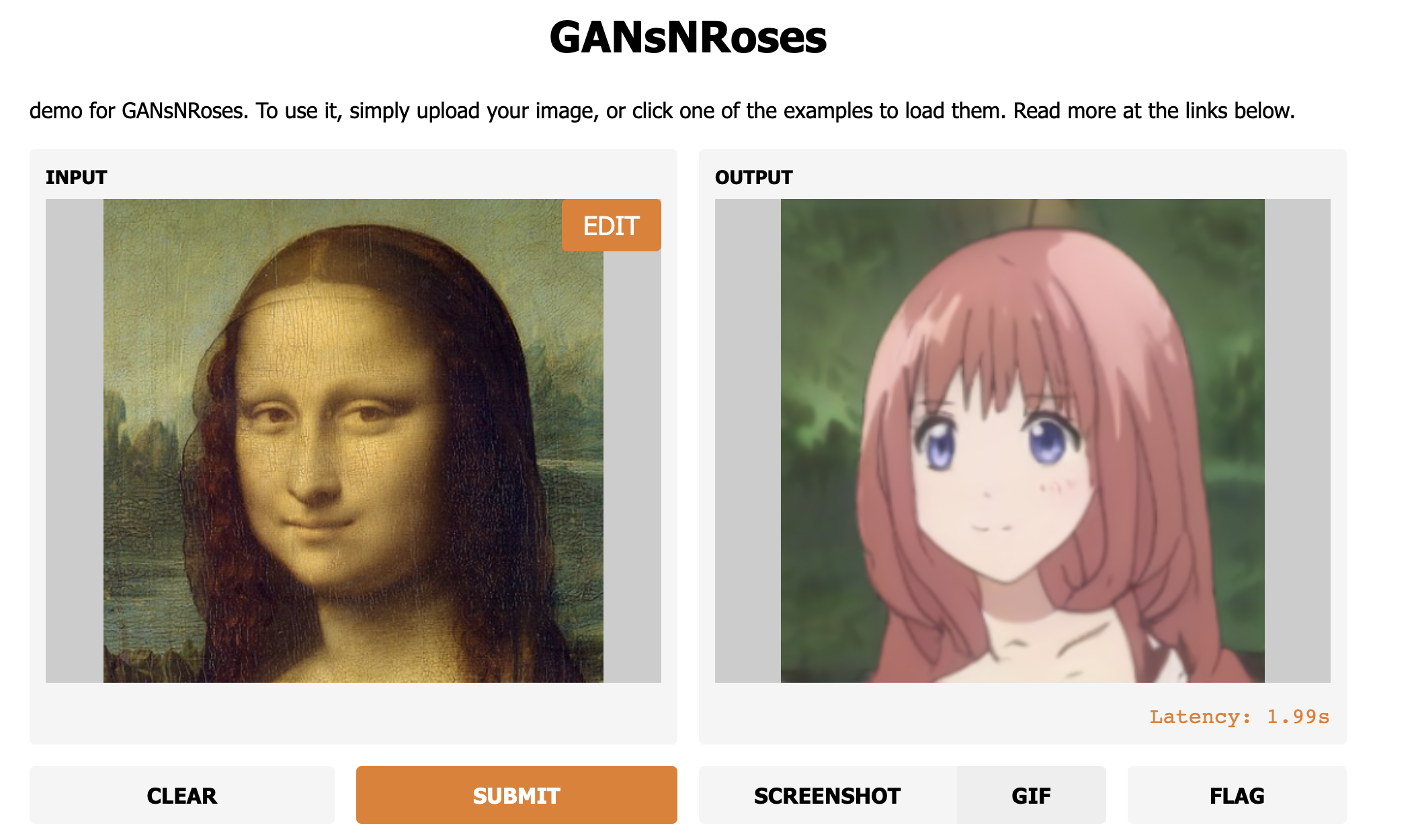
Official PyTorch repo for GAN’s N’ Roses. Diverse im2im and vid2vid selfie to anime translation.

Abstract:
We show how to learn a map that takes a content code, derived from a face image, and a randomly chosen style code to an anime image. We derive an adversarial loss from our simple and effective definitions of style and content. This adversarial loss guarantees the map is diverse – a very wide range of anime can be produced from a single content code. Under plausible assumptions, the map is not just diverse, but also correctly represents the probability of an anime, conditioned on an input face. In contrast, current multimodal generation procedures cannot capture the complex styles that appear in anime. Extensive quantitative experiments support the idea the map is correct. Extensive qualitative results show that the method can generate a much more diverse range of styles than SOTA comparisons. Finally, we show that our formalization of content and style allows us to perform video to video translation without ever training on videos.
New
Dependency
conda install --yes -c pytorch pytorch=1.7.1 torchvision cudatoolkit=<CUDA_VERSION>
pip install tqdm gdown kornia scipy opencv-python dlib moviepy lpips aubio ninja
Dataset
The dataset we use for training is the selfie2anime dataset from UGATIT. You can also use your own dataset in the following format.
└── YOUR_DATASET_NAME
├── trainA
├── xxx.jpg (name, format doesn't matter)
├── yyy.png
└── ...
├── trainB
├── zzz.jpg
├── www.png
└── ...
├── testA
├── aaa.jpg
├── bbb.png
└── ...
└── testB
├── ccc.jpg
├── ddd.png
└── ...
Training
For training you might want to switch to train branch in order to use custom cuda kernel codes. Otherwise, it will use the Pytorch native implementation.
python train.py --name EXP_NAME --d_path YOUR_DATASET_NAME --batch BATCH_SIZE
The full model checkpoint is here if you wish to you it for finetuning etc.
Inference
Our notebook provides a comprehensive demo of both image and video translation. Pretrained model is automatically downloaded.
Citation
If you use this code or ideas from our paper, please cite our paper:
@misc{chong2021gans,
title={GANs N' Roses: Stable, Controllable, Diverse Image to Image Translation (works for videos too!)},
author={Min Jin Chong and David Forsyth},
year={2021},
eprint={2106.06561},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
Acknowledgments
This code borrows heavily from StyleGAN2 by rosalinity and partly from UGATIT.
GitHub
https://github.com/mchong6/GANsNRoses
Source: https://pythonawesome.com/diverse-im2im-and-vid2vid-selfie-to-anime-translation/